About RAID Technology
RAID is an acronym as “redundant array of inexpensive disks” or “redundant array of independent disks”. "RAID" is now used as an umbrella term for computer data storage schemes that can divide and replicate data among multiple hard disk drives. The different schemes/architectures are named by the word RAID followed by a number, as in RAID 0, RAID 1, etc. Raid’s various designs involve two key design goals: increase data reliability and/or increase input/output performance. When multiple physical disks are set up to use RAID technology, they are said to be in a RAID array. This array distributes data across multiple disks, but the array is seen by the computer user and operating system as one single disk. RAID can be set up to serve several different purposes.
Purpose and basics
Redundancy is achieved by either writing the same data to multiple drives (known as mirroring), or collecting data (known as parity data) across the array, calculated such that the failure of one (or possibly more, depending on the type of RAID) disks in the array will not result in loss of data. A failed disk may be replaced by a new one, and the lost data reconstructed from the remaining data and the parity data
How Parity Is Calculated, and How Failed Drives Are Rebuilt
Parity data in a RAID environment is calculated using the Boolean "XOR" function. For example, lets take a simple RAID 4 three disk setup consisting of two drives that hold 8 bits of data each, and a third drive (Drive 3) that will be used to hold our parity data.
Drive1:01101101
Drive 2: 11010100
To calculate parity for the two drives, we perform an XOR on their data.
i.e. 01101101 XOR 11010100 = 10111001
The resulting parity data, 10111001, is then stored on Drive 3, our dedicated parity drive.
Now, should any of the three drives fail, the contents of the dead drive can be reconstructed on a replacement ("hot spare") drive by taking the data from the remaining drives, and subjecting them to the same XOR calculation. For the sake of the example, let’s suppose Drive 2 dies. To rebuild Drive 2, we take the XOR of the contents of the two remaining drives.. Drive 3 and Drive 1:
Drive3:10111001
Drive1:01101101
i.e. 10111001 XOR 01101101 = 11010100
There are various combinations of these approaches giving different trade-offs of protection against data loss, capacity, and speed. RAID levels 0, 1, and 5 are the most commonly found, and cover most requirements.
• RAID 0 (striped disks) distributes data across several disks in a way that gives improved speed at any given instant. If one disk fails, however, all of the data on the array will be lost, as there is neither parity nor mirroring. In this regard, RAID 0 is somewhat of a misnomer, in that RAID is 0 is non-redundant. A RAID 0 array requires a minimum of two drives.
• RAID 1 mirrors the contents of the disks, making a form of 1:1 ratio real-time backup. The contents of each disk in the array are identical to that of every other disk in the array. A RAID 1 array requires a minimum of two drives.
• RAID 4 (striped disks with dedicated parity) combines three or more disks in a way that protects data against loss of any one disk. The storage capacity of the array is reduced by one disk. A RAID 3 array requires a minimum of three drives; two to hold striped data, and a third drive to hold parity data.
• RAID 5 (striped disks with distributed parity) combines three or more disks in a way that protects data against the loss of any one disk. The storage capacity of the array is a function of the number of drives minus the space needed to store parity.
• RAID 6 (striped disks with dual parity) combines four or more disks in a way that protects data against loss of any two disks.
• RAID 10 (or 1+0) is a mirrored data set (RAID 1) which is then striped (RAID 0), hence the "1+0" name. A RAID 10 array requires a minimum of two drives, but is more commonly implemented with 4 drives to take advantage of speed benefits.
• RAID 01 (or 0+1) is a striped data set (RAID 0) which is then mirrored. (RAID 1). A RAID 01 array requires a minimum of four drives; Two to hold the striped data, plus another two required to mirror the pair.
RAID can involve significant computation when reading and writing information. With traditional "real" RAID hardware, a separate controller does this computation. In other cases the operating system or simpler and less expensive controllers require the host computer's processor to do the computing, which reduces the computer's performance on processor-intensive tasks (see Operating system based ("software RAID") and Firmware/driver-based RAID below). Simpler RAID controllers may provide only levels 0 and 1, which require less processing.
RAID systems with redundancy continue working without interruption when one (or possibly more, depending on the type of RAID) disks of the array fail, although they are then vulnerable to further failures. When the bad disk is replaced by a new one the array is rebuilt while the system continues to operate normally. Some systems have to be powered down when removing or adding a drive; others support hot swapping, allowing drives to be replaced without powering down. RAID with hot-swapping is often used in high availability systems, where it is important that the system remains running as much of the time as possible.
RAID is not a good alternative to backing up data. Data may become damaged or destroyed without harm to the drive(s) on which they are stored. For example, some of the data may be overwritten by a system malfunction; a file may be damaged or deleted by user error or malice and not noticed for days or weeks; and, of course, the entire array is at risk of physical damage.
Note that a RAID controller itself can become the single point of failure within a system.
Principles
RAID combines two or more physical hard disks into a single logical unit by using either special hardware or software. Hardware solutions often are designed to present themselves to the attached system as a single hard drive, so that the operating system would be unaware of the technical workings. For example, you might configure a 1TB RAID 5 array using three 500GB hard drives in hardware RAID, the operating system would simply be presented with a "single" 1TB volume. Software solutions are typically implemented in the operating system and would present the RAID drive as a single volume to applications running upon the operating system.
There are three key concepts in RAID: mirroring, the copying of data to more than one disk; striping, the splitting of data across more than one disk; and error correction, where redundant data is stored to allow problems to be detected and possibly fixed (known as fault tolerance). Different RAID levels use one or more of these techniques, depending on the system requirements. RAID's main aim can be either to improve reliability and availability of data, ensuring that important data is available more often than not (e.g. a database of customer orders), or merely to improve the access speed to files (e.g. for a system that delivers video on demand TV programs to many viewers).
The configuration affects reliability and performance in different ways. The problem with using more disks is that it is more likely that one will fail, but by using error checking the total system can be made more reliable by being able to survive and repair the failure. Basic mirroring can speed up reading data as a system can read different data from both the disks, but it may be slow for writing if the configuration requires that both disks must confirm that the data is correctly written. Striping is often used for performance, where it allows sequences of data to be read from multiple disks at the same time. Error checking typically will slow the system down as data needs to be read from several places and compared. The design of RAID systems is therefore a compromise and understanding the requirements of a system is important. Modern disk arrays typically provide the facility to select the appropriate RAID configuration.
Standard RAID Levels:
RAID0
A RAID 0 (also known as a stripe set or striped volume) splits data evenly across two or more disks (striped) with no parity information for redundancy. It is important to note that RAID 0 was not one of the original RAID levels and provides no data redundancy. RAID 0 is normally used to increase performance, although it can also be used as a way to create a small number of large virtual disks out of a large number of small physical ones.
A RAID 0 can be created with disks of differing sizes, but the storage space added to the array by each disk is limited to the size of the smallest disk. For example, if a 120 GB disk is striped together with a 100 GB disk, the size of the array will be 200 GB.

RAID 0 failure rate
Although RAID 0 was not specified in the original RAID paper, an idealized implementation of RAID 0 would split I/O operations into equal-sized blocks and spread them evenly across two disks. RAID 0 implementations with more than two disks are also possible, though the group reliability decreases with member size.
Reliability of a given RAID 0 set is equal to the average reliability of each disk divided by the number of disks in the set:
That is, reliability (as measured by mean time to failure (MTTF) or mean time between failures (MTBF) is roughly inversely proportional to the number of members – so a set of two disks is roughly half as reliable as a single disk. If there were a probability of 5% that the disk would fail within three years, in a two disk array, that probability would be upped-to
The reason for this is that the file system is distributed across all disks. When a drive fails the file system cannot cope with such a large loss of data and coherency since the data is "striped" across all drives (the data cannot be recovered without the missing disk). Data can be recovered using special tools, however, this data will be incomplete and most likely corrupt, and data recovery is typically very costly and not guaranteed.
RAID 0 performance
While the block size can technically be as small as a byte, it is almost always a multiple of the hard disk sector size of 512 bytes. This lets each drive seek independently when randomly reading or writing data on the disk. How much the drives act independently depends on the access pattern from the file system level. For reads and writes that are larger than the stripe size, such as copying files or video playback, the disks will be seeking to the same position on each disk, so the seek time of the array will be the same as that of a single drive. For reads and writes that are smaller than the stripe size, such as database access, the drives will be able to seek independently. If the sectors accessed are spread evenly between the two drives, the apparent seek time of the array will be half that of a single drive (assuming the disks in the array have identical access time characteristics). The transfer speed of the array will be the transfer speed of all the disks added together, limited only by the speed of the RAID controller. Note that these performance scenarios are in the best case with optimal access patterns.
RAID 0 is useful for setups such as large read-only NFS servers where mounting many disks is time-consuming or impossible and redundancy is irrelevant.
RAID 1

A RAID 1 creates an exact copy (or mirror) of a set of data on two or more disks. This is useful when read performance or reliability are more important than data storage capacity. Such an array can only be as big as the smallest member disk. A classic RAID 1 mirrored pair contains two disks (see diagram), which increases reliability geometrically over a single disk. Since each member contains a complete copy of the data, and can be addressed independently, ordinary wear-and-tear reliability is raised by the power of the number of self-contained copies.
RAID 1 failure rate
As a trivial example, consider a RAID 1 with two identical models of a disk drive with a 5% probability that the disk would fail within three years. Provided that the failures are statistically independent, then the probability of both disks failing during the three year lifetime is
Thus, the probability of losing all data is 0.25% if the first failed disk is never replaced. If only one of the disks fails, no data would be lost, assuming the failed disk is replaced before the second disk fails.
However, since two identical disks are used and since their usage patterns are also identical, their failures can not be assumed to be independent. Thus, the probability of losing all data, if the first failed disk is not replaced, is considerably higher than 25% but still below 5%.
RAID 1 performance
Since all the data exists in two or more copies, each with its own hardware, the read performance can go up roughly as a linear multiple of the number of copies. That is, a RAID 1 array of two drives can be reading in two different places at the same time, though not all implementations of RAID 1 do this.[4] To maximize performance benefits of RAID 1, independent disk controllers are recommended, one for each disk. Some refer to this practice as splitting or duplexing. When reading, both disks can be accessed independently and requested sectors can be split evenly between the disks. For the usual mirror of two disks, this would, in theory, double the transfer rate when reading. The apparent access time of the array would be half that of a single drive. Unlike RAID 0, this would be for all access patterns, as all the data are present on all the disks. In reality, the need to move the drive heads to the next block (to skip blocks already read by the other drives) can effectively mitigate speed advantages for sequential access. Read performance can be further improved by adding drives to the mirror. Many older IDE RAID 1 controllers read only from one disk in the pair, so their read performance is always that of a single disk. Some older RAID 1 implementations would also read both disks simultaneously and compare the data to detect errors. The error detection and correction on modern disks makes this less useful in environments requiring normal availability. When writing, the array performs like a single disk, as all mirrors must be written with the data. Note that these performance scenarios are in the best case with optimal access patterns.
RAID 1 has many administrative advantages. For instance, in some environments, it is possible to "split the mirror": declare one disk as inactive, do a backup of that disk, and then "rebuild" the mirror. This is useful in situations where the file system must be constantly available. This requires that the application supports recovery from the image of data on the disk at the point of the mirror split. This procedure is less critical in the presence of the "snapshot" feature of some file systems, in which some space is reserved for changes, presenting a static point-in-time view of the file system. Alternatively, a new disk can be substituted so that the inactive disk can be kept in much the same way as traditional backup. To keep redundancy during the backup process, some controllers support adding a third disk to an active pair. After a rebuild to the third disk completes, it is made inactive and backed up as described above.
RAID 2

A RAID 2 stripes data at the bit (rather than block) level, and uses a Hamming code for error correction. The disks are synchronized by the controller to spin in perfect tandem. Extremely high data transfer rates are possible. This is the only original level of RAID that is not currently used.
The use of the Hamming(7,4) code (four data bits plus three parity bits) also permits using 7 disks in RAID 2, with 4 being used for data storage and 3 being used for error correction.
RAID 2 is the only standard RAID level, other than some implementations of RAID 6, which can automatically recover accurate data from single-bit corruption in data. Other RAID levels can detect single-bit corruption in data, or can sometimes reconstruct missing data, but cannot reliably resolve contradictions between parity bits and data bits without human intervention.
(Multiple-bit corruption is possible though extremely rare. RAID 2 can detect but not repair double-bit corruption.)
All hard disks soon after implemented an error correction code that also used Hamming code, so RAID 2's error corrections was now redundant and added unnecessary complexity. Like RAID 3, this level quickly became useless and it is now obsolete. There are no commercial applications of RAID 2.
RAID 3

A RAID 3 uses byte-level striping with a dedicated parity disk. RAID 3 is very rare in practice. One of the side effects of RAID 3 is that it generally cannot service multiple requests simultaneously. This comes about because any single block of data will, by definition, be spread across all members of the set and will reside in the same location. So, any I/O operation requires activity on every disk and usually requires synchronized spindles.
In our example, a request for block "A" consisting of bytes A1-A6 would require all three data disks to seek to the beginning (A1) and reply with their contents. A simultaneous request for block B would have to wait.
However, the performance characteristic of RAID 3 is very consistent, unlike higher RAID levels, the size of a stripe is less than the size of a sector or OS block so that, for both reading and writing, the entire stripe is accessed every time. The performance of the array is therefore identical to the performance of one disk in the array except for the transfer rate, which is multiplied by the number of data drives (i.e., less parity drives).
This makes it best for applications that demand the highest transfer rates in long sequential reads and writes, for example uncompressed video editing. Applications that make small reads and writes from random places over the disk will get the worst performance out of this level.[6]
The requirement that all disks spin synchronizedly, aka in lockstep, added design considerations to a level that didn't give significant advantages over other RAID levels, so it quickly became useless and it's nowadays obsolete.[5] Both RAID 3 and RAID 4 were quickly replaced by RAID 5.[7] However, this level has commercial vendors making implementations of it. It's usually implemented in hardware, and the performance issues are addressed by using large disk caches.
RAID 4

Diagram of a RAID 4 setup with dedicated parity disk with each color representing the group of blocks in the respective parity block (a stripe)
A RAID 4 uses block-level striping with a dedicated parity disk. This allows each member of the set to act independently when only a single block is requested. If the disk controller allows it, a RAID 4 set can service multiple read requests simultaneously. RAID 4 looks similar to RAID 5 except that it does not use distributed parity, and similar to RAID 3 except that it stripes at the block level, rather than the byte level. Generally, RAID 4 is implemented with hardware support for parity calculations, and a minimum of 3 disks is required for a complete RAID 4 configuration.
In the example on the right, a read request for block A1 would be serviced by disk 0. A simultaneous read request for block B1 would have to wait, but a read request for B2 could be serviced concurrently by disk 1.
Unfortunately for writing the parity disk becomes a bottleneck, as simultaneous writes to A1 and B2 would in addition to the writes to their respective drives also both need to write to the parity drive. In this way RAID example 4 places a very high load on the parity drive in an array.
The performance of RAID 4 in this configuration can be very poor, but unlike RAID 3 it does not need synchronized spindles. However if RAID 4 is implemented on synchronized drives and the size of a stripe is reduced below the OS block size a RAID 4 array then has the same performance pattern as a RAID 3 array.
Currently, RAID 4 is only implemented at the enterprise level by only one company, NetApp, who solved the performance problems discussed above with their proprietary WAFL file system. Both RAID 3 and RAID 4 were quickly replaced by RAID 5.
RAID 5

Diagram of a RAID 5 setup with distributed parity with each color representing the group of blocks in the respective parity block (a stripe). This diagram shows left asymmetric algorithm
A RAID 5 uses block-level striping with parity data distributed across all member disks. RAID 5 has achieved popularity because of its low cost of redundancy. This can be seen by comparing the number of drives needed to achieve a given capacity. RAID 1 or RAID 1+0, which yield redundancy, give only s / 2 storage capacity, where s is the sum of the capacities of n drives used. In RAID 5, the yield is . As an example, four 1TB drives can be made into a 2 TB redundant array under RAID 1 or RAID 1+0, but the same four drives can be used to build a 3 TB array under RAID 5. Although RAID 5 is commonly implemented in a disk controller, some with hardware support for parity calculations (hardware RAID cards) and some using the main system processor (motherboard based RAID controllers), it can also be done at the operating system level, e.g., using Windows Dynamic Disks or with mdadm in Linux. A minimum of three disks is required for a complete RAID 5 configuration. In some implementations a degraded RAID 5 disk set can be made (three disk set of which only two are online), while mdadm supports a fully-functional (non-degraded) RAID 5 setup with two disks - which function as a slow RAID-1, but can be expanded with further volumes.
In the example, a read request for block A1 would be serviced by disk 0. A simultaneous read request for block B1 would have to wait, but a read request for B2 could be serviced concurrently by disk 1.
RAID 5 parity handling
A concurrent series of blocks (one on each of the disks in an array) is collectively called a stripe. If another block, or some portion thereof, is written on that same stripe, the parity block, or some portion thereof, is recalculated and rewritten. For small writes, this requires...
• Read the old data block
• Read the old parity block
• Compare the old data block with the write request. For each bit that has flipped (changed from 0 to 1, or from 1 to 0) in the data block, flip the corresponding bit in the parity block
• Write the new data block
• Write the new parity block
The disk used for the parity block is staggered from one stripe to the next, hence the term distributed parity blocks. RAID 5 writes are expensive in terms of disk operations and traffic between the disks and the controller.
The parity blocks are not read on data reads, since this would be unnecessary overhead and would diminish performance. The parity blocks are read, however, when a read of blocks in the stripe and within the parity block in the stripe are used to reconstruct the errant sector. The CRC error is thus hidden from the main computer. Likewise, should a disk fail in the array, the parity blocks from the surviving disks are combined mathematically with the data blocks from the surviving disks to reconstruct the data on the failed drive on-the-fly.
This is sometimes called Interim Data Recovery Mode. The computer knows that a disk drive has failed, but this is only so that the operating system can notify the administrator that a drive needs replacement; applications running on the computer are unaware of the failure. Reading and writing to the drive array continues seamlessly, though with some performance degradation.
RAID 5 disk failure rate
The maximum number of drives in a RAID 5 redundancy group is theoretically unlimited, but it is common practice to limit the number of drives. The tradeoffs of larger redundancy groups are greater probability of a simultaneous double disk failure, the increased time to rebuild a redundancy group, and the greater probability of encountering an unrecoverable sector during RAID reconstruction. As the number of disks in a RAID 5 group increases, the mean time between failures (MTBF, the reciprocal of the failure rate) can become lower than that of a single disk. This happens when the likelihood of a second disk's failing out of N − 1 dependent disks, within the time it takes to detect, replace and recreate a first failed disk, becomes larger than the likelihood of a single disk's failing.
Solid-state drives (SSDs) may present a revolutionary instead of evolutionary way of dealing with increasing RAID-5 rebuild limitations. With encouragement from many flash-SSD manufacturers, JEDEC is preparing to set standards in 2009 for measuring UBER (uncorrectable bit error rates) and "raw" bit error rates (error rates before ECC, error correction code).[8] But even the economy-class Intel X25-M SSD claims an unrecoverable error rate of 1 sector in 1015 bits and an MTBF of two million hours.[9] Ironically, the much-faster throughput of SSDs (STEC claims its enterprise-class Zeus SSDs exceed 200 times the transactional performance of today's 15k-RPM, enterprise-class HDDs)[10] suggests that a similar error rate (1 in 1015) will result a two-magnitude shortening of MTBF
RAID 5 performance
RAID 5 implementations suffer from poor performance when faced with a workload which includes many writes which are smaller than the capacity of a single stripe.[citation needed] This is because parity must be updated on each write, requiring read-modify-write sequences for both the data block and the parity block. More complex implementations may include a non-volatile write back cache to reduce the performance impact of incremental parity updates.
Random write performance is poor, especially at high concurrency levels common in large multi-user databases. The read-modify-write cycle requirement of RAID 5's parity implementation penalizes random writes by as much as an order of magnitude compared to RAID 0.[11]
Performance problems can be so severe that some database experts have formed a group called BAARF — the Battle Against Any Raid Five.[12]
The read performance of RAID 5 is almost as good as RAID 0 for the same number of disks. Except for the parity blocks, the distribution of data over the drives follows the same pattern as RAID 0. The reason RAID 5 is slightly slower is that the disks must skip over the parity blocks.
In the event of a system failure while there are active writes, the parity of a stripe may become inconsistent with the data. If this is not detected and repaired before a disk or block fails, data loss may ensue as incorrect parity will be used to reconstruct the missing block in that stripe. This potential vulnerability is sometimes known as the write hole. Battery-backed cache and similar techniques are commonly used to reduce the window of opportunity for this to occur. The same issue occurs for RAID-6.
RAID 5 usable size
Parity data uses up the capacity of one drive in the array (this can be seen by comparing it with RAID 4: RAID 5 distributes the parity data across the disks, while RAID 4 centralizes it on one disk, but the amount of parity data is the same). If the drives vary in capacity, the smallest of them sets the limit. Therefore, the usable capacity of a RAID 5 array is , where N is the total number of drives in the array and Smin is the capacity of the smallest drive in the array.
The number of hard disks that can belong to a single array is limited only by the capacity of the storage controller in hardware implementations, or by the OS in software RAID. One caveat is that unlike RAID 1, as the number of disks in an array increases, the chance of data loss due to multiple drive failures is increased. This is because there is a reduced ratio of "losable" drives (the number of drives which may fail before data is lost) to total drives.
RAID 6

Diagram of a RAID 6 setup, which is identical to RAID 5 other than the addition of a second parity block
Redundancy and data loss recovery capability
RAID 6 extends RAID 5 by adding an additional parity block; thus it uses block-level striping with two parity blocks distributed across all member disks. It was not one of the original RAID levels.
Performance (speed)
RAID 6 does not have a performance penalty for read operations, but it does have a performance penalty on write operations because of the overhead associated with parity calculations. Performance varies greatly depending on how RAID 6 is implemented in the manufacturer's storage architecture – in software, firmware or by using firmware and specialized ASICs for intensive parity calculations. It can be as fast as a RAID-5 system with one less drive (same number of data drives)
Efficiency (potential waste of storage)
RAID 6 is no more space inefficient than RAID 5 with a hot spare drive when used with a small number of drives, but as arrays become bigger and have more drives the loss in storage capacity becomes less important and the probability of data loss is greater. RAID 6 provides protection against data loss during an array rebuild; when a second drive is lost, a bad block read is encountered, or when a human operator accidentally removes and replaces the wrong disk drive when attempting to replace a failed drive. The usable capacity of a RAID 6 array is , where N is the total number of drives in the array and Smin is the capacity of the smallest drive in the array.
Implementation
According to the Storage Networking Industry Association (SNIA), the definition of RAID 6 is: "Any form of RAID that can continue to execute read and write requests to all of a RAID array's virtual disks in the presence of any two concurrent disk failures. Several methods, including dual check data computations (parity and Reed-Solomon), orthogonal dual parity check data and diagonal parity, have been used to implement RAID Level 6.
Nested RAID Levels:
Levels of nested RAID, also known as hybrid RAID, combine two or more of the standard levels of RAID (redundant array of independent disks) to gain performance and/or additional redundancy.
When nesting RAID levels, a RAID type that provides redundancy is typically combined with RAID 0 to boost performance. With these configurations it is preferable to have RAID 0 on top and the redundant array at the bottom, because fewer disks then need to be regenerated when a disk fails. (Thus, RAID 1+0 is preferable to RAID 0+1 but the administrative advantages of "splitting the mirror" of RAID 1 would be lost. It should be noted, however, that the on-disk layout of blocks for RAID 1+0 and RAID 0+1 setups are identical so these limitations are purely in the software).
RAID 0+1 or 01

A RAID 0+1 (also called RAID 01, not to be confused with RAID 10), is a RAID level used for both replicating and sharing data among disks. The minimum amount of disks required to implement this level of RAID is 4. The difference between RAID 0+1 and RAID 1+0 is the location of each RAID system — RAID 0+1 is a mirror of stripes. The size of a RAID 0+1 array can be calculated as follows where n is the number of drives (must be even) and c is the capacity of the smallest drive in the array:
Typical RAID 0+1 setup.
Six-drive RAID 0+1
Consider an example of RAID 0+1: six 120 GB drives need to be set up on a RAID 0+1. Below is an example where two 360 GB level 0 arrays are mirrored, creating 360 GB of total storage space:
Note: A1, A2, et cetera each represent one data block; each column represents one disk.
The maximum storage space here is 360 GB, spread across two arrays. The advantage is that when a hard drive fails in one of the level 0 arrays, the missing data can be transferred from the other array. However, adding an extra hard drive to one stripe requires you to add an additional hard drive to the other stripes to balance out storage among the arrays.
It is not as robust as RAID 10 and cannot tolerate two simultaneous disk failures, unless the second failed disk is from the same stripe as the first. That is, once a single disk fails, each of the mechanisms in the other stripe is single point of failure. Also, once the single failed mechanism is replaced, in order to rebuild its data all the disks in the array must participate in the rebuild.
The exception to this is if all the disks are hooked up to the same RAID controller in which case the controller can do the same error recovery as RAID 10 as it can still access the functional disks in each RAID 0 set. If you compare the diagrams between RAID 0+1 and RAID 10 and ignore the lines above the disks you will see that all that's different is that the disks are swapped around. If the controller has a direct link to each disk it can do the same. In this one case there is no difference between RAID 0+1 and RAID 10.
Additionally, bit error correction technologies have not kept up with rapidly rising drive capacities, resulting in higher risks of encountering media errors. In the case where a failed drive is not replaced in a RAID 0+1 configuration, a single uncorrectable media error occurring on the mirrored hard drive would result in data loss.
Given these increasing risks with RAID 0+1, many business and mission critical enterprise environments are beginning to evaluate more fault tolerant RAID setups that add underlying disk parity. Among the most promising are hybrid approaches such as RAID 51 (mirroring above single parity) or RAID 61 (mirroring above dual parity).
RAID 10 (RAID 1+0)

Typical RAID 10 setup.
A RAID 1+0, sometimes called RAID 1&0, or RAID 10, is similar to a RAID 0+1 with exception that the RAID levels used are reversed — RAID 10 is a stripe of mirrors. Below is an example where three collections of 120 GB level 1 arrays are striped together to make 360 GB of total storage space:
Redundancy and data-loss recovery capability
All but one drive from each RAID 1 set could fail without damaging the data. However, if the failed drive is not replaced, the single working hard drive in the set then becomes a single point of failure for the entire array. If that single hard drive then fails, all data stored in the entire array is lost. As is the case with RAID 0+1, if a failed drive is not replaced in a RAID 10 configuration then a single uncorrectable media error occurring on the mirrored hard drive would result in data loss. Some RAID 10 vendors address this problem by supporting a "hot spare" drive, which automatically replaces and rebuilds a failed drive in the array.
Given these increasing risks with RAID 10, many business and mission critical enterprise environments are beginning to evaluate more fault tolerant RAID setups that add underlying disk parity. Among the most promising are hybrid approaches such as RAID 50 (stripe above single parity) or RAID 60 (stripe above dual parity).
Performance (speed)
RAID 10 has traditionally been the primary choice for high-load databases, because the lack of parity to calculate gives it faster write speeds. This may be true of older, low-end storage solutions, or software RAID arrays, but RAID 5's "write pentalty" has been essentially eliminated in recent years given advances in hardware controllers and techniques such as write-behind caching.
Implementation
The Linux kernel RAID10 implementation (from version 2.6.9 and onwards) is not nested. The mirroring and striping is done in one process. Only certain layouts are standard RAID 10 with the rest being proprietary. See also the Linux MD RAID 10 and RAID 1.5 sections in the Non-standard RAID article for details.
RAID 0+3 and 3+0
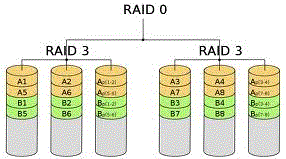
RAID 30
RAID level 30 is also known as striping of dedicated parity arrays. It is a combination of RAID level 3 and RAID level 0. RAID 30 provides high data transfer rates, combined with high data reliability. RAID 30 is best implemented on two RAID 3 disk arrays with data striped across both disk arrays. RAID 30 breaks up data into smaller blocks, and then stripes the blocks of data to each RAID 3 raid set. RAID 3 breaks up data into smaller blocks, calculates parity by performing an Exclusive OR on the blocks, and then writes the blocks to all but one drive in the array. The parity bit created using the Exclusive OR is then written to the last drive in each RAID 3 array. The size of each block is determined by the stripe size parameter, which is set when the RAID is created.
One drive from each of the underlying RAID 3 sets can fail. Until the failed drives are replaced the other drives in the sets that suffered such a failure are a single point of failure for the entire RAID 30 array. In other words, if one of those drives fails, all data stored in the entire array is lost. The time spent in recovery (detecting and responding to a drive failure, and the rebuild process to the newly inserted drive) represents a period of vulnerability to the RAID set.
RAID 100 (RAID 1+0+0)

A RAID 100, sometimes also called RAID 10+0, is a stripe of RAID 10s. This is logically equivalent to a wider RAID 10 array, but is generally implemented using software RAID 0 over hardware RAID 10. Being "striped two ways", RAID 100 is described as a "plaid RAID". [3] Below is an example in which two sets of four 120 GB RAID 1 arrays are striped and re-striped to make 480 GB of total storage space:
Representative RAID-100 Setup.
(Note: A1, B1, et cetera each represent one data sector; each column represents one disk.)
The failure characteristics are identical to RAID 10: all but one drive from each RAID 1 set could fail without loss of data. However, the remaining disk from the RAID 1 becomes a single point of failure for the already degraded array. Often the top level stripe is done in software. Some vendors call the top level stripe a MetaLun (Logical Unit Number (LUN)), or a Soft Stripe.
The major benefits of RAID 100 (and plaid RAID in general) over single-level RAID is spreading the load across multiple RAID controllers, giving better random read performance and mitigating hotspot risk on the array. For these reasons, RAID 100 is often the best choice for very large databases, where the hardware RAID controllers limit the number of physical disks allowed in each standard array. Implementing nested RAID levels allows virtually limitless spindle counts in a single logical volume.
RAID 50 (RAID 5+0)

(Note: A1, B1, et cetera each represent one data block; each column represents one disk; Ap, Bp, et cetera each represent parity information for each distinct RAID 5 and may represent different values across the RAID 5 (that is, Ap for A1 and A2 can differ from Ap for A3 and A4).)
A RAID 50 combines the straight block-level striping of RAID 0 with the distributed parity of RAID 5. This is a RAID 0 array striped across RAID 5 elements. It requires at least 6 drives.
Below is an example where three collections of 240 GB RAID 5s are striped together to make 720 GB of total storage space:
One drive from each of the RAID 5 sets could fail without loss of data. However, if the failed drive is not replaced, the remaining drives in that set then become a single point of failure for the entire array. If one of those drives fails, all data stored in the entire array is lost. The time spent in recovery (detecting and responding to a drive failure, and the rebuild process to the newly inserted drive) represents a period of vulnerability to the RAID set.
In the example below, datasets may be striped across both RAID sets. A dataset with 5 blocks would have 3 blocks written to the first RAID set, and the next 2 blocks written to RAID set 2.
RAID-50 Setup consisting of two sets of four drives each.
The configuration of the RAID sets will impact the overall fault tolerance. A construction of three seven-drive RAID 5 sets has higher capacity and storage efficiency, but can only tolerate three maximum potential drive failures. Because the reliability of the system depends on quick replacement of the bad drive so the array can rebuild, it is common to construct three six-drive RAID5 sets each with a hot spare that can immediately start rebuilding the array on failure. This does not address the issue that the array is put under maximum strain reading every bit to rebuild the array precisely at the time when it is most vulnerable. A construction of seven three-drive RAID 5 sets can handle as many as seven drive failures but has lower capacity and storage efficiency.
RAID 50 improves upon the performance of RAID 5 particularly during writes, and provides better fault tolerance than a single RAID level does. This level is recommended for applications that require high fault tolerance, capacity and random positioning performance.
As the number of drives in a RAID set increases, and the capacity of the drives increase, this impacts the fault-recovery time correspondingly as the interval for rebuilding the RAID set increases.
RAID 60 (RAID 6+0)

A RAID 60 combines the straight block-level striping of RAID 0 with the distributed double parity of RAID 6. That is, a RAID 0 array striped across RAID 6 elements. It requires at least 8 disks.
Below is an example where two collections of 240 GB RAID 6s are striped together to make 480 GB of total storage space
RAID-60 (RAID 6+0) Setup consisting of two sets of four drives each.
As it is based on RAID 6, two disks from each of the RAID 6 sets could fail without loss of data. Also failures while a single disk is rebuilding in one RAID 6 set will not lead to data loss. RAID 60 has improved fault tolerance; any two drives can fail without data loss and up to four totals as long as it is only two from each RAID6 sub-array.
Striping helps to increase capacity and performance without adding disks to each RAID 6 set (which would decrease data availability and could impact performance). RAID 60 improves upon the performance of RAID 6. Despite the fact that RAID 60 is slightly slower than RAID 50 in terms of writes due to the added overhead of more parity calculations, when data security is concerned this performance drop may be negligible.
No comments:
Post a Comment